Thanks for your feedback!
EDIT
Para garantir uma performance rápida e estável para todos os usuários, recomendamos a adoção destas boas práticas ao consultar a Sensedia Analytics API.
Estas recomendações são especialmente importantes em ambientes com alto volume de dados e múltiplos consumidores, pois contribuem diretamente para a estabilidade do cluster, redução de latência e melhor experiência com a plataforma.
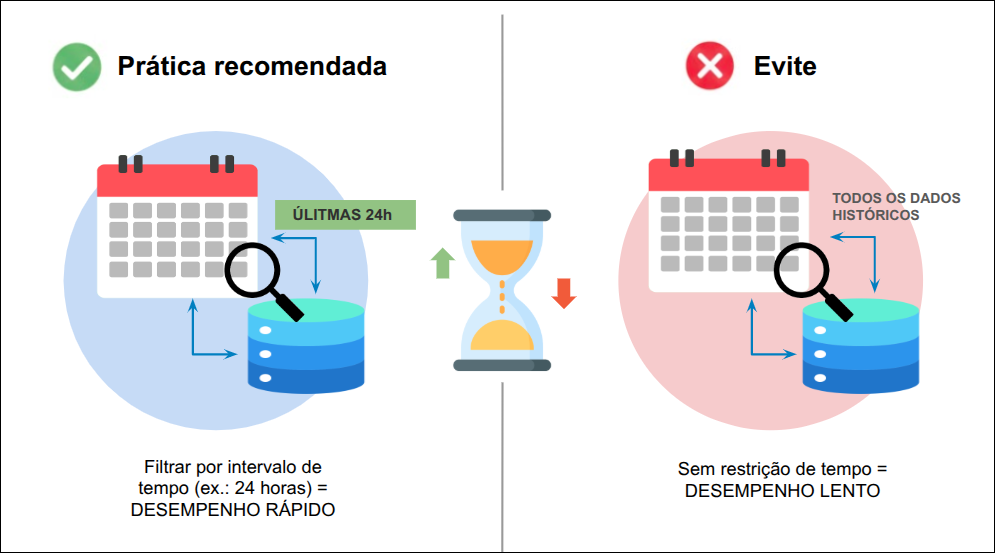
A busca em dados temporais é otimizada quando os índices seguem o padrão de séries temporais (time-series).
Prática recomendada: Sempre inclua um filtro de intervalo de tempo (range query) em suas consultas.
Evite: Consultas que tentam buscar dados de todo o histórico sem restrição de tempo.
Otimização: Restringir a consulta ao menor período de tempo necessário melhora significativamente o desempenho. Por exemplo, consultar 24 horas de dados é muito mais rápido do que consultar 30 dias.

Restringir o número de documentos retornados em uma única chamada é essencial para o desempenho da rede e da busca.
Utilize paginação:
Use parâmetros como size e from (ou page e limit) para controlar a quantidade de resultados retornados e o deslocamento inicial da consulta.
Limite inteligente:
Mantenha o size (limite de documentos por requisição) em um valor razoável, por exemplo, no máximo 1.000 ou 10.000 registros, conforme a capacidade do seu ambiente.
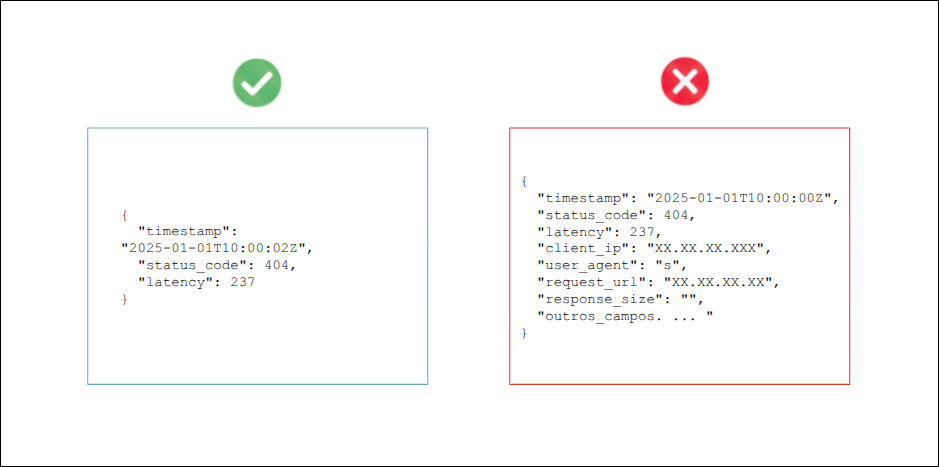
Por padrão, o OpenSearch retorna o documento JSON completo (_source).
Se sua aplicação consome apenas alguns campos, especifique exatamente quais são necessários.
Utilize _source_includes ou parâmetros de campos:
Solicite somente os campos que serão utilizados, por exemplo: fields=timestamp,status_code,latency.
Benefício: Reduz significativamente o consumo de largura de banda e o tempo de processamento no cluster OpenSearch.
Agregações são utilizadas para o cálculo de métricas, como contagens, médias e somas, e geralmente representam a parte mais custosa da consulta.
Filtre antes de agregar:
Sempre aplique filtros rigorosos — especialmente o filtro de tempo — antes de executar agregações.
Quanto menos documentos precisarem ser processados, mais rápida será a resposta.
Evite agregações de alta cardinalidade:
Evite agrupar por campos com um número extremamente alto de valores únicos, como IDs de transação.
Prefira campos com cardinalidade controlada, como status_code ou api_name.
Limitação de buckets: Não solicite um número excessivo de buckets em uma única agregação. Se precisar de mais de 100 buckets, considere realizar múltiplas consultas ou utilizar técnicas de amostragem.
A forma como você realiza as buscas impacta diretamente a performance.
Escolha correta do tipo de busca:
Utilize term exclusivamente para buscas exatas em campos do tipo keyword e match para buscas em campos analisados de texto completo, evitando o processamento desnecessário de texto.
Evite o uso de consultas com wildcard (*) ou expressões regulares, pois exigem varredura extensiva do índice e consomem muito mais CPU e I/O.
Se for usar wildcard:
Evite iniciar a expressão com o caractere "*".
Por exemplo, prefira api_name* em vez de *api_name.
Ordenar resultados é uma operação dispendiosa e deve ser evitada sempre que possível.
Prática recomendada: Se a ordenação padrão por timestamp em ordem decrescente for suficiente, evite especificar campos adicionais para ordenação.
Quando for necessário ordenar:
Prefira campos numéricos ou de data que não sejam analisados (campos do tipo keyword).
Evite ordenar por campos de texto não estruturado.
Ao seguir estas diretrizes, a velocidade das consultas poderá ser maximizada, contribuindo para a manutenção da performance ideal do ambiente da plataforma Sensedia Analytics.
Share your suggestions with us!
Click here and then [+ Submit idea]